Ok, first of all apologies to all of you guys for being away so long, I was very busy. Still am, but I have recently completed an upgrade of the Sourcefire system to version 6.2.0, so I thought to share my experience with you…
First things first. I strongly recommend to check out our article about upgrade from 5.3.x to 5.4.x and upgrade from 5.4 to 6.0. Many things said there actually apply to this article.
Our starting point is 6.0.1 on both FMC (Firepower Management Center) and four modules on ASA5525-X running 9.4(2) code. At the end of this article, we are going to run 6.2.0 on FMC and modules and ASA will run 9.7.1
As with previous upgrade, we cannot just hop from 6.0.1 to 6.2.0. As with the ASA upgrade, we also have to be careful and follow required steps. We cannot (in most cases) skip from one version to the latest. One another important thing to mention is that we have to make sure that ASA software version is aligned with the SFR module version. So, we must upgrade ASA code before SFR code, and we have to upgrade FMC before we upgrade SFR code. Makes sense? So, in summary, these are the major steps we will follow:
- Upgrade ASA code from 9.4(2) to 9.7.1
- Upgrade FMC from 6.0.1 to 6.2.0
- Upgrade two SFR modules from 6.0.1 to 6.2.0
- Reimage remaining two modules to 6.2.0
One could ask, why upgrading two modules and reimaging another two? Well, just to show that we have options here. There could be several version in a path from current module version to the newest. If there is one or two, it may be good idea to do the upgrade process. However, there could be many versions and it may be quicker to reimage the modules to the latest release.
Here what needs to be done in a little bit more details:
- Check upgrade paths and read release notes
- Download all required images and verify hashes
- Upload ASA and ASDM images to ASA boxes
- Upload FMC and module images to the management center
- Upgrade ASA boxes
- Apply policies to the modules and check the overall health
- Make backup of FMC or/and make a snapshot if running virtual
- Upgrade FMC by following array of versions
- Upgrade or reimage SFR modules
- Reapply policies and check health
Upgrade ASA code to 9.7.1
Like said previously, we cannot go from version X to version Y just by removing old image and booting new one. Here is the upgrade path to version 9.7.1 at the time of this writing:

If we check this table, we can see that we can safely go straight from 9.4(2) to 9.7.1. If we were not this lucky, then we have to go from one version to latest one by doing the upgrade in several steps. We can refresh our knowledge about upgrading the ASA code here. One question remains unanswered so far and that is why 9.7.1? Well, this is why:

Upgrade FMC to 6.1.0
Also with the FMC we cannot just skip to the latest version. Here is the table illustrating our upgrade path:

As we are at 6.0.1, we need to follow these upgrade steps to reach 6.2.0: 6.0.1 -> 6.1.0 Pre-Install -> 6.1.0 -> 6.1.0 Hotfix -> 6.2.0. For that purpose we need to obtain, upload and run the following images in the given order:

Some upgrades require reboot and others don’t. Anyhow, when we verify that this is actually what we want to do and we click the install button, the process will begin. It is very important to be patient here and not to interrupt the process. This WILL take a lot of time, for example:

So, don’t panic! If we planned all well, all will do well. It is important to know that no traffic interruption will occur while we upgrade the FMC, so we can stay cool.
Once we upgrade to 6.1.0, we have the option to do an upgrade readiness check, so if we are not ready, the check will tell us. Here we can run readiness check or go directly to upgrade:



We could also get a fail result from the readiness check, for example:

Here we can see a log file which we need to check out in order to find what went wrong. In this example, we find the main upgrade log file (main_upgrade_script.log), list its contents and see which upgrade script has failed:

As we can see, the script called “000_start/108_check_sensors_ver.pl” has failed. If we take a look at the log file for that script, we can see a reason it failed. By the way, the log file is named after the script name by appending .log extension:

So, we cannot upgrade FMC to 6.2.0, while we have modules running 6.0.1. They have to be at least 6.1. Once again, it is very important to make note of the upgrade paths. For ASA, FMC and modules.
At this point it is clear that we need to upgrade modules to at least 6.1 in order to upgrade FMC furhter. So, once we are at 6.1 with management center, we need to make modules running 6.1 as well. Once two modules are at 6.1, we will proceed with management center upgrade to 6.2 and then upgrade those two remaining modules to 6.2 as well. Stay with me here, we will upgrade two of four modules, the remaining two modules we will reimage. But if we don’t want to follow upgrade path for those two modules, we won’t be able to upgrade FMC. Because of that, we will remove those two modules from the FMC, upgrade FMC to 6.2, upgrade first two modules to 6.2 and then reimage remaining modules and reattach them to the management center.
Upgrade SFR modules to 6.1.0
We have already saw how modules are upgraded in previous article. Going from that article to 6.2.0 requires certain upgrade path, as follows:

As we can see, the upgrade path is the same as with FMC. Here I clearly marked that this hotfix needs to be installed after upgrading to 6.1.0.
Upgrading modules sometimes will require reboots and if reboot happens the traffic flow will stop, so we have to have this in mind. Either we plan for the downtime or we stop sending the traffic from ASA to the module until upgrade is completed.
These are images we will install:

Of course, the last step will be performed after management center is at version 6.2.0.
As per two previous images, we need to install the following versions:
- Cisco_Network_Sensor_6.1.0_Pre-install-6.0.1.999-30.sh
- Cisco_Network_Sensor_Upgrade-6.1.0-330.sh
- Cisco_Network_Sensor_Hotfix_AF-6.1.0.2-1.sh
Upgrade FMC to 6.2.0
There is not much really here different from the steps we took so far. We select appropriate upgrade, do a readiness check and finally upgrade to 6.2.0. Once we have a success upgrade, the message pops up:

We reapply policies and check system health. If we are ok we proceed to….
Upgrade SFR modules to 6.2.0
Again, not much special here. If we followed all right paths up to here, then this step is an easy one. Readiness check, planned downtime or stopping the traffic to go through the module, reboot, policy reapply and health check.
Reimaging modules
This is fun 🙂
Not that all other stuff is not, but this is something we did not cover on this blog so far. The last two modules are in A/S firewall cluster. So far we have upgraded first two nodes to 9.7.1, similar to instructions given here. Now the plan is to reimage standby unit while the active is passing the traffic. After we reimage the standby module and reattach it to the management center, we make current standby ASA active, do the same with the other ASA and optionally we switch back that last ASA to be primary again. All with no traffic interruption.
First, we upload SFR boot images to both firewall nodes. We don’t upload system images, because we will pick them up from FTP server in the process.
Before we wipe modules clean, we may make a note about their network settings, so we can set them in correct state after we do reimaging. From the ASA command line interface:

Uploading boot images:
copy ftp://ftpuser:password@10.x.y.1/asasfr-5500x-boot-6.2.0-2.img disk0:
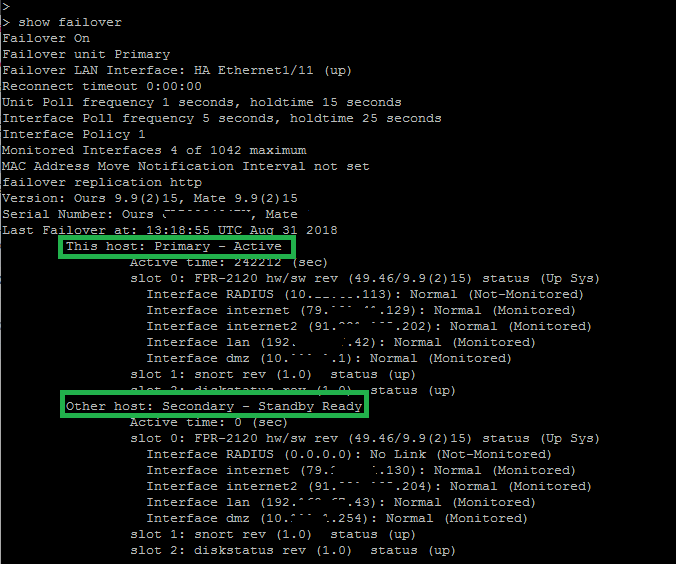
Before we begin, it is good idea to verify the failover status. We don’t want to reimage the software on one ASA if the other one is in a bad shape. Now we shutdown the module:
asa/sec/stby#
asa/sec/stby# sw-module module sfr shutdown
Shutdown module sfr? [confirm]
Shutdown issued for module sfr.
asa/sec/stby#
By issuing “show module sfr details” we confirm that the module status is down, and we remove the module:
asa/sec/stby#
asa/sec/stby# sw-module module sfr uninstall
Module sfr will be uninstalled. This will completely remove the disk image assocated with the sw-module including any configuration that existed within it.
Uninstall module sfr? [confirm]
Uninstall issued for module sfr.
asa/sec/stby#
After a while, the status of the module should be “Down No Image Present”. In order to install a new image, we need to point to new boot image:
asa/sec/stby#
asa/sec/stby#
asa/sec/stby# sw-module module sfr recover configure image disk0:/asasfr-5500x-boot-6.2.0-2.img
asa/sec/stby#
Of course, that command is typed in one line 🙂
We then boot the image:
asa/sec/stby#
asa/sec/stby# sw-module module sfr recover boot
Module sfr will be recovered. This may erase all configuration and all data
on that device and attempt to download/install a new image for it. This may take
several minutes.
Recover module sfr? [confirm]
asa/sec/stby#
The only solid reason for booting this image is to set up temporary network parameters to be able to fetch the system image and begin the software installation. We can see the interaction in the article Installing Cisco ASA FirePOWER software module. There is one difference here. In above mentioned article, the credentials for configuring module in the second stage were “admin/Sourcefire” and now they are “admin/Admin123“.
After the boot module setup is complete we will be presented with the basic prompt from which we can start download and installation of the system image, the application itself:
system install ftp://10.x.y.1/asasfr-sys-6.2.0-362.pkg
Once the download and installation is completed, we need to reattach the module to the FMC:
>
> configure manager add 10.a.b.67 somepassword
Manager successfully configured.
Finally, we go to the management center and add this module. We know how to that from this article.
We are not done yet. Because we removed this module from FMC, after we attach it back on, we need to license the module, reassign interfaces to appropriate zones and reapply policies. If all is ok, and the health is all green, we make this ASA active, so this module begin passing the traffic and do the same process for the other module.
At this point, we have our FMC and all four modules at 6.2.0 🙂
Final note: I did my best to make steps in this article error free. This did the trick for me, but I have spent days in preparation, reading documentation, guides and so on. Please use this article as an addition to all other stuff you should check before going live with this, especially in production environment.
Thanks for reading and see you next time…